1. 事象
PHPからPostgreSQLに接続しようとすると、pg_connect(): Unable to connect to PostgreSQL server: SCRAM authentication requires libpq version 10 or above.というエラーが発生する。
2. 環境
– windows10
– xampp
– PHP 7.2
– PostgresSQL 14.4
3. 原因
PostgreSQLの認証方式SCRAM-SHA-256に基づいたエラー。
具体的には、「この認証方式にはlibpq 10以降が必要だが、使用中のバージョンは libpq 9以前のものである」というもの。
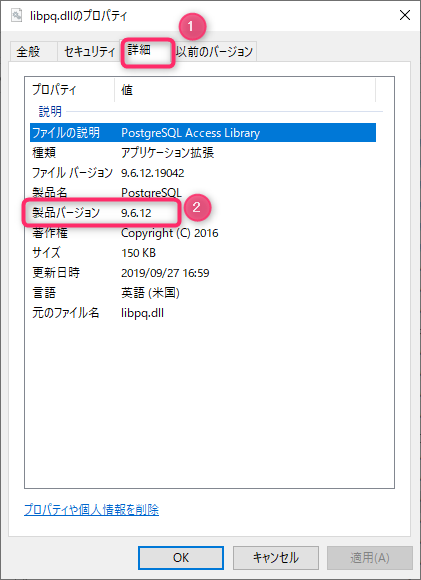
3.1 libpq のバージョン確認方法
xamppの場合。
– エクスプローラで C:\xampp\php に移動
– libpq を、右クリック→プロパティを選択
– プロパティ画面の詳細タブを選択
<div style=”clear:both;”></div>
4. 対策
PHP を、バージョン8以降に更新すればlibpq 10がインストールされるとのこと(未確認)。
PHPを何らかの事情でバージョンアップできない場合は、認証方式を以下の通り変更する。(stackoverflow から)
- Step 1:
C:\Program Files\PostgreSQL\14\data から postgresql.confを探し、password_encryption = md5を設定する(96行目付近)。
|
|
#password_encryption = scram-sha-256 # scram-sha-256 or md5 # → 上の行のコメントを外し md5 に変更する password_encryption = md5 |
- Step 2: 同じ
C:\Program Files\PostgreSQL\14\data から pg_hba.conf を探し、METHOD 列の scram-sha-256 を全て md5 に変更する。(85行目付近から最後まで)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only #local all all scram-sha-256 local all all trust # IPv4 local connections: #host all all 127.0.0.1/32 scram-sha-256 host all all 127.0.0.1/32 trust # IPv6 local connections: #host all all ::1/128 scram-sha-256 host all all ::1/128 trust # Allow replication connections from localhost, by a user with the # replication privilege. #local replication all scram-sha-256 #host replication all 127.0.0.1/32 scram-sha-256 #host replication all ::1/128 scram-sha-256 local replication all trust host replication all 127.0.0.1/32 trust host replication all ::1/128 trust |
(上では、scram-sha-256をコメントアウトし、md5の行を追加している。)
- Step 3: windowsターミナル(または、コマンドプロンプトやPoweshee)を開き、 ‘psql -U postgres’ を実行して、インストール時のパスワードを入力する(パスワードは不要かもしれない)。
|
|
psql -U postgres postgres=# |
- Step 4: 次に、パスワードを再設定する(同じもので良い)。
|
|
postres=# ALTER USER postgres WITH PASSWORD 'new-password' |
- 最後に: PostgreSQLとApacheを再起動する。
5. 参考
参考に、PHP 接続確認用のプログラムを添付する。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
<?php $dsn = 'pgsql:dbname=dvdrental host=localhost port=5432'; $user = 'postgres'; $password = 'tsuchi'; try{ $conn = new PDO($dsn, $user, $password); print('接続に成功しました。<br>'); }catch (PDOException $e){ print('Error:'.$e->getMessage()); die(); } $conn = null; ?> |
6. その他
Ruby Rails でも同様のエラーが発生するとのこと。
対策は、こちらを参考のこと。
(追記)この対策以前、R からも接続できなかったが、今日再度実行したら接続できたことからすると、原因はこの認証方式にあったものと思考される。
実行例を以下に示す。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
library(DBI) library(RPostgreSQL) dsn_database = "dvdrental" # name of Database dsn_hostname = "localhost" # Host name dsn_port = "5432" # port number dsn_uid = "postgres" # username dsn_pwd = "パスワード" # password tryCatch({ drv <- dbDriver("PostgreSQL") print("Connecting to Database…") con <- dbConnect(drv, dbname = dsn_database, host = dsn_hostname, port = dsn_port, user = dsn_uid, password = dsn_pwd) print("Database Connected!") }, error=function(cond) { print("Unable to connect to Database.") print(cond) }) df <- dbGetQuery(con, "SELECT * FROM city") head(df) cnt <- dbGetQuery(con, "select count(*) from city") cnt dbDisconnect(con) |
なお、dvdrental データベースの作成方法は、こちらを参考。