XML DOM - ノードのナビゲート
ノードは、ノード・リレーションを使ってナビゲートすることができます。
DOMノードのナビゲート
ノード間のリレーションを通してノードツリーのノードにアクセスすることを、"ノードのナビゲート" と言います。
XML DOMでは、ノード・リレーションは、ノードのプロパティとして定義されています:
- parentNode
- childNodes
- firstChild
- lastChild
- nextSibling
- previousSibling
次のイメージは、ノードツリーの一部とbooks.xmlのノード間のリレーションを図示しています:
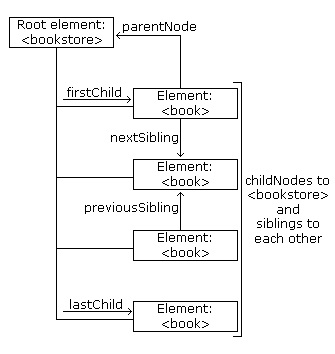
DOM - 親ノード
すべてのノードは、確実に1つの親ノードを持っています。 以下のコードは、<book> の親ノードにナビゲートします:
例
xmlDoc=loadXMLDoc("books.xml");
x=xmlDoc.getElementsByTagName("book")[0];
document.write(x.parentNode.nodeName);
|
試してください »
|
例の説明:
- loadXMLDoc() を用い、xmlDocに "books.xml" をロードします
- 最初の <book> 要素を取得します
- "x" の親ノードのノード名を出力します
空のテキストノードの回避
Firefox を始めとし、他のいくつかのブラウザは、空白または改行をテキストノードとみなしますが、Internet Explorer は異ります。
これは、プロパティ: firstChild、lastChild、nextSibling、previousSibling を使用する時に問題が起きます。
空のテキストノード(要素ノード間のスペースと改行文字)へナビゲートすることを避けるために、ノードタイプをチェックする関数を使います:
function get_nextSibling(n)
{
y=n.nextSibling;
while (y.nodeType!=1)
{
y=y.nextSibling;
}
return y;
} |
上記関数は、プロパティ node.nextSibling の代わりに、get_nextSibling(ノード)を使えるようにします。
コードの説明:
要素ノードのタイプは 1 です。もし兄弟ノードが要素ノードでなければ、
要素ノードが見つかるまで、次のノードへ移動します。
この方法で、結果が Internet Explorer と Firefox で同じになります。
最初の子要素の取得
次のコードは、最初の <book> の最初の要素ノードを表示します:
例
<html>
<head>
<script type="text/javascript" src="loadxmldoc.js">
</script>
<script type="text/javascript">
//check if the first node is an element node
function get_firstChild(n)
{
y=n.firstChild;
while (y.nodeType!=1)
{
y=y.nextSibling;
}
return y;
}
</script>
</head>
<body>
<script type="text/javascript">
xmlDoc=loadXMLDoc("books.xml");
x=get_firstChild(xmlDoc.getElementsByTagName("book")[0]);
document.write(x.nodeName);
</script>
</body>
</html>
|
出力:
試してください »
|
例の説明:
- loadXMLDoc() を用い、xmlDoc に
"books.xml" をロードします
- 要素ノードの最初の子ノードを取得するために、最初の <book> 要素ノードの get_firstChild fucntion を使用します
- 要素ノードである最初の子ノードのノード名を出力します
 |
他の例 |
lastChild()
この例は、ノードの最後の子ノードを得るために、lastChild()メソッドとカスタムの関数を使用します
nextSibling()
この例は、ノードの次の兄弟ノードを取得するために、nextSibling()メソッドとカスタム関数を使用します
previousSibling()
この例は、ノードの前の兄弟ノードを取得するために、previousSibling()メソッドとカスタム関数を使用します
|